Evaluating Uplift Models
One of the most widespread applications of causal inference in the industry is uplift modeling, a.k.a. the estimation of Conditional Average Treatment Effects.
When estimating the causal effect of a treatment (a drug, ad, product, …) on an outcome of interest (a disease, firm revenue, customer satisfaction, …), we are often not only interested in understanding whether the treatment works on average, but we would like to know for which subjects (patients, users, customers, …) it works better or worse.
Estimating heterogeneous incremental effects, or uplift, is an essential intermediate step to improve targeting of the policy of interest. For example, we might want to warn certain people that they are more likely to experience side effects from a drug or show an advertisement only to a specific set of customers.
While there exist many methods to model uplift, it is not always clear which one to use in a specific application. Crucially, because of the fundamental problem of causal inference, the objective of interest, the uplift, is never observed, and therefore we cannot validate our estimators as we would do with a machine learning prediction algorithm. We cannot set aside a validation set and pick the best-performing model since we have no ground truth, not even in the validation set, and not even if we ran a randomized experiment.
What can we do then? In this article, I try to cover the most popular methods used to evaluate uplift models. If you are unfamiliar with uplift models, I suggest first reading my introductory article.
https://towardsdatascience.com/8a9c1e340832
Uplift and Promotional Emails
Imagine we were working in the marketing department of a product company interested in improving our email marketing campaign. Historically, we mostly sent emails to new customers. However, now we would like to adopt a data-driven approach and target customers for whom the email has the highest positive impact on revenue. This impact is also called uplift or incrementality.
Let’s have a look at the data we have at our disposal. I import the data-generating process dgp_promotional_email() from src.dgp. I also import some plotting functions and libraries from src.utils.
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
from src.utils import *
from src.dgp import dgp_promotional_email
dgp = dgp_promotional_email(n=500)
df = dgp.generate_data()
df.head()
| new | age | sales_old | sales | ||
|---|---|---|---|---|---|
| 0 | 0 | 32.42 | 0.11 | 1 | 0.03 |
| 1 | 1 | 34.92 | 0.36 | 0 | 0.47 |
| 2 | 1 | 41.00 | 0.49 | 0 | 0.40 |
| 3 | 0 | 50.02 | 0.35 | 1 | 0.53 |
| 4 | 0 | 33.34 | 0.12 | 1 | 0.02 |
We have information on 500 customers, for whom we observe whether they are new customers, their age, the sales they generated before the email campaign (sales_old), whether they were sent the mail, and the sales after the email campaign.
The outcome of interest is sales, which we denote with the letter Y. The treatment or policy that we would like to improve is the mail campaign, which we denote with the letter W. We call all the remaining variables confounders or control variables and we denote them with X.
Y = 'sales'
W = 'mail'
X = ['age', 'sales_old', 'new']
The Dyrected Acyclic Graph (DAG) representing the causal relationships between the variables is the following. The causal relationship of interest is depicted in green.
flowchart TD
classDef included fill:#DCDCDC,stroke:#000000,stroke-width:3px;
W((mail))
Y((sales))
X1((new))
X2((age))
X3((sales old))
W --> Y
X1 --> W
X1 --> Y
X2 --> Y
X3 --> Y
class W,Y,X1,X2,X3 included;
linkStyle 0 stroke:#2db88b,stroke-width:6px;
linkStyle 1,2,3,4 stroke:#003f5c,stroke-width:6px;
From the DAG we see that the new customer indicator is a confounder and needs to be controlled for in order to identify the effect of mail on sales. age and sales_old instead are not essential for estimation but could be helpful for identification. For more information on DAGs and control variables, you can check my introductory article.
https://towardsdatascience.com/b63dc69e3d8c
The objective of uplift modeling is to recover the Individual Treatment Effects (ITE) $\tau_i$, i.e. the incremental effect on sales of sending the promotional mail. We can express the ITE as the difference between two hypothetical quantities: the potential outcome of the customer if they had received the email, $Y_i^{(1)}$, minus the potential outcome of the customer if they had not received the email, $Y_i^{(0)}$.
$$
\tau_i = Y_i^{(1)} - Y_i^{(0)}
$$
Note that for each customer, we only observe one of the two realized outcomes, depending on whether they actually received the mail or not. Therefore, the ITE are inherently unobservable. What can be estimated instead is the Conditional Average Treatment Effect (CATE) i.e., the expected individual treatment effect $\tau_i$, conditional on covariates X. For example, the average effect of the mail on sales for older customers (age > 50).
$$
\tau(x) = \mathbb{E} \Big[ \ \tau_i \ \Big| \ X_i = x \Big]
$$
In order to be able to recover the CATE, we need to make three assumptions.
-
Unconfoundedness: $Y^{(0)}, Y^{(1)} \perp W \ | \ X$
-
Overlap: $0 < e(X) < 1$
-
Consistency: $Y = W \cdot Y^{(1)} + (1-W) \cdot Y^{(0)}$
Where $e(X)$ is the propensity score i.e., the expected probability of being treated, conditional on covariates X. $$ e(x) = \mathbb{E} \Big[ \ W_i \ \Big| \ X_i = x \Big] $$
In what follows, we will use machine learning methods to estimate the CATE $\tau(x)$, the propensity scores $e(x)$, and the conditional expectation function (CEF) of the outcome, $\mu(x)$ $$ \mu(x) = \mathbb{E} \Big[ \ Y_i \ \Big| \ X_i = x \Big] $$
We use Random Forest Regression algorithms to model the CATE and the outcome CEF, while we use Logistic Regression to model the propensity score.
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LogisticRegressionCV
model_tau = RandomForestRegressor(max_depth=2)
model_y = RandomForestRegressor(max_depth=2)
model_e = LogisticRegressionCV()
In this article, we do not fine-tune the underlying machine learning models, but fine-tuning is strongly recommended to improve the accuracy of uplift models (for example, with auto-ml libraries like FLAML).
Uplift Models
There exist many methods to model uplift or, in other words, to estimate Conditional Average Treatment Effects (CATE). Since the objective of this article is to compare methods to evaluate uplift models, we will not explain the methods in detail. For a gentle introduction, you can check my introductory article on meta learners.
The learners that we will consider are the following:
-
S-learner or single-learner, introduced by Kunzel, Sekhon, Bickel, Yu (2017)
-
T-learner or two-learner, introduced by Kunzel, Sekhon, Bickel, Yu (2017)
-
X-learner or cross-learner, introduced by Kunzel, Sekhon, Bickel, Yu (2017)
-
R-learner or Robinson-learner introduced by Nie, Wager (2017)
-
DR-learner or doubly-robust-learner, introduced by Kennedy (2022)
We import all the model from Microsoft’s econml library.
from src.learners_utils import *
from econml.metalearners import SLearner, TLearner, XLearner
from econml.dml import NonParamDML
from econml.dr import DRLearner
S_learner = SLearner(overall_model=model_y)
T_learner = TLearner(models=clone(model_y))
X_learner = XLearner(models=model_y, propensity_model=model_e, cate_models=model_tau)
R_learner = NonParamDML(model_y=model_y, model_t=model_e, model_final=model_tau, discrete_treatment=True)
DR_learner = DRLearner(model_regression=model_y, model_propensity=model_e, model_final=model_tau)
We fit() the models on the data, specifying the outcome variable Y, the treatment variable W and covariates X.
names = ['SL', 'TL', 'XL', 'RL', 'DRL']
learners = [S_learner, T_learner, X_learner, R_learner, DR_learner]
for learner in learners:
learner.fit(df[Y], df[W], X=df[X])
We are now ready to evaluate the models! Which model should we choose?
Oracle Loss Functions
The main problem of evaluating uplift models is that, even with a validation set and even with a randomized experiment or AB test, we do not observe our metric of interest: the Individual Treatment Effects. In fact, we only observe the realized outcomes, $Y_i^{(0)}$ for untreated customers and $Y_i^{(1)}$ for treated customers. Therefore, for no customer we can compute the individual treatment effect in the validation data, $\tau_i = Y_i^{(1)} - Y_i^{(0)}$.
Can we still do something to evaluate our estimators?
The answer is yes, but before giving more details, let’s first understand what we would do if we could observe the Individual Treatment Effects $\tau_i$.
Oracle MSE Loss
If we could observe the individual treatment effects (but we don’t, hence the “oracle” attribute), we could try to measure how far our estimates $\hat{\tau}(X_i)$ are from the true values $\tau_i$. This is what we normally do in machine learning when we want to evaluate a prediction method: we set aside a validation dataset and we compare predicted and true values on that data. There exist plenty of loss functions to evaluate prediction accurary, so let’s concentrate on the most popular one: the Mean Squared Error (MSE) loss.
$$ \mathcal{L} _ {oracle-MSE}(\hat{\tau}) = \frac{1}{n} \sum _ {i=1}^{n} \left( \hat{\tau}(X_i) - \tau(X_i) \right)^2 $$
def loss_oracle_mse(data, learner):
tau = learner.effect(data[X])
return np.mean((tau - data['effect_on_sales'])**2)
The function compare_methods prints and plots evaluation metrics computed on a separate validation dataset.
def compare_methods(learners, names, loss, title=None, subtitle='lower is better'):
data = dgp.generate_data(seed_data=1, seed_assignment=1, keep_po=True)
results = pd.DataFrame({
'learner': names,
'loss': [loss(data.copy(), learner) for learner in learners]
})
fig, ax = plt.subplots(1, 1, figsize=(6, 4))
sns.barplot(data=results, x="learner", y='loss').set(ylabel='')
plt.suptitle(title, y=1.02)
plt.title(subtitle, fontsize=12, fontweight=None, y=0.94)
return results
compare_methods(learners, names, loss_oracle_mse, title='Oracle MSE Loss')
| learner | loss | |
|---|---|---|
| 0 | SL | 0.002932 |
| 1 | TL | 0.004637 |
| 2 | XL | 0.000936 |
| 3 | RL | 0.000990 |
| 4 | DRL | 0.000577 |
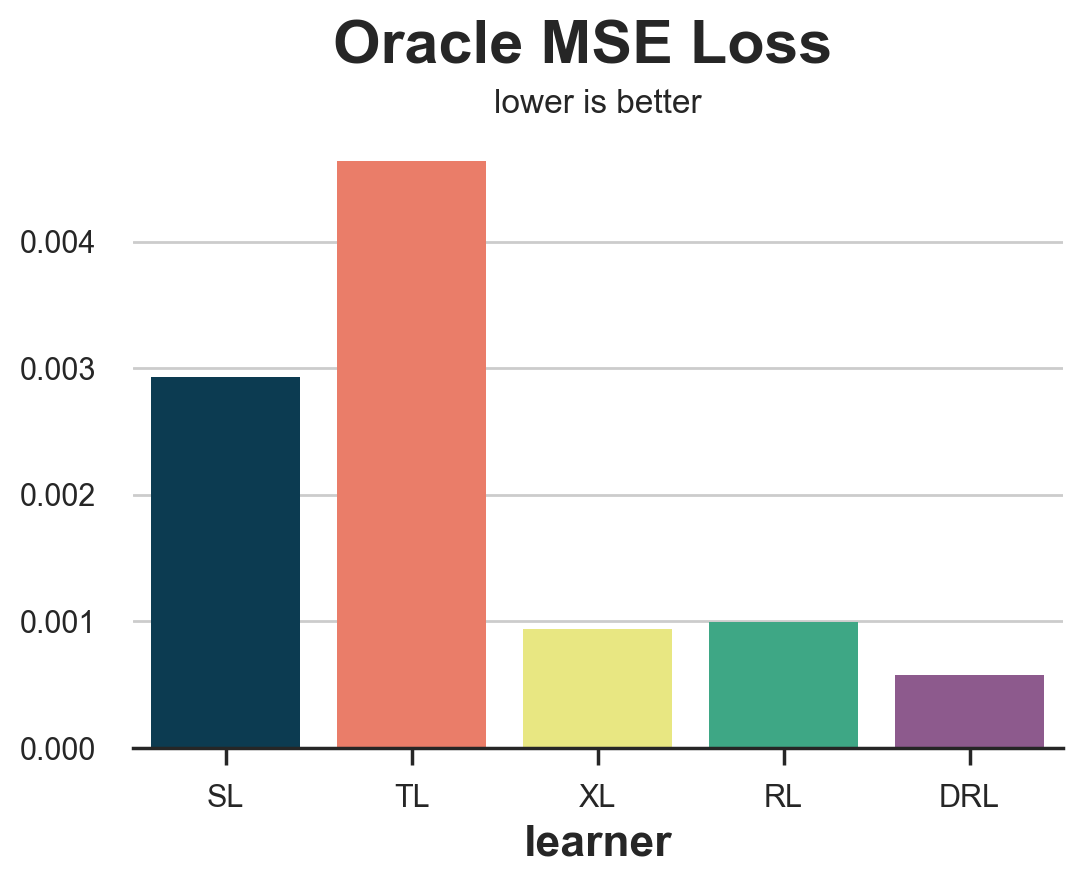
In this case, we see that the T-learner clearly performs worst, with the S-learner just behind. On the other hand, the X-, R- and DR-learners perform significantly better, with the DR-learner winning the race.
However, this might not be the best loss function to evaluate our uplift model. In fact, uplift modeling is just an intermediate step towards our ultimate goal: improving revenue.
Oracle Policy Gain
Since our ultimate goal is to improve revenue, we could evaluate estimators by how much they increase revenue, given a certain policy function. Suppose, for example, that we had a $0.01$\$ cost of sending an email. Then, our policy would be to treat each costumer that has a predicted Conditional Average Treatment Effect above $0.01$\$.
cost = 0.01
How much would our revenue actually increase? Let’s define with $d(\hat{\tau})$ our policy function, such that $d=1$ if $\tau >= 0.1$ and $d=0$ otherwise. Then our gain (higher is better) function is: $$ \mathcal{G} _ {oracle-POLICY}(\hat{\tau}) = \frac{1}{n} \sum _ {i=1}^{n} d(\hat{\tau}) (\tau_i - c) $$
Again, this is an “oracle” loss function that cannot be computed in reality since we do not observe the individual treatment effects.
def gain_oracle_policy(data, learner):
tau_hat = learner.effect(data[X])
return np.sum((data['effect_on_sales'] - cost) * (tau_hat > cost))
compare_methods(learners, names, gain_oracle_policy, title='Oracle Policy Gain', subtitle='higher is better')
| learner | loss | |
|---|---|---|
| 0 | SL | 0.00 |
| 1 | TL | 4.23 |
| 2 | XL | 10.98 |
| 3 | RL | 10.43 |
| 4 | DRL | 12.33 |
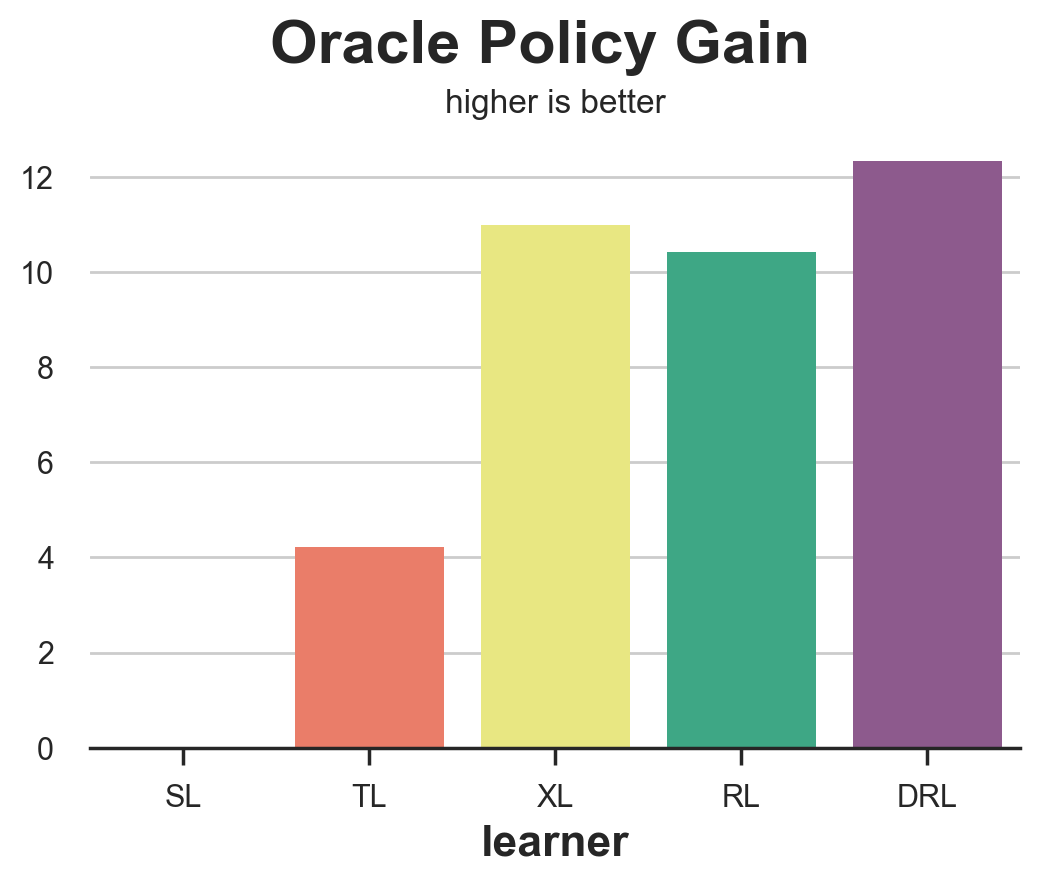
In this case, the S-learner is clearly the worst performer, leading to no effect on revenues. The T-learner leads to modest gains while the X-, R- and DR- learners all lead to aggregate gains, with the X-learner slightly ahead.
Practical Loss Functions
In the previous section, we have seen two examples of loss functions that we would like to compute if we could observe the Individual Treatment Effects $\tau_i$. However, in practice, even with a randomized experiment and even with a validation set, we do not observe the ITE,our object of interest. We will now cover some measures that try to evaluate uplift models, given this practical constraint.
Outcome Loss
The first and simplest approach is to switch to a different loss variable. While we cannot observe the Individual Treatment Effects, $\tau_i$, we can still observe our outcome $y_i$. This is not exactly our object of interest, but we might expect an uplift model that performs well in terms of predicting $y$ to also produce good estimates of $\tau$.
One such loss function could be the Outcome MSE loss, which is the usual MSE loss function for prediction methods. $$ \mathcal{L}_{Y}(\hat{\mu}) = \frac{1}{n} \sum _ {i=1}^{n} \Big( \hat{\mu}(X_i, W_i) - Y_i \Big)^2 $$
The problem here is that not all models directly produce an estimate of $\mu(x)$ and, even when they do, it is not the object of interest.
Prediction to Prediction Loss
Another very simple approach could be to compare the predictions of the model trained on the training set with the predictions of another model trained on the validation set. While intuitive, this appraoch could be extremely misleading.
def loss_pred(data, learner):
tau = learner.effect(data[X])
learner2 = copy.deepcopy(learner).fit(data[Y], data[W], X=data[X])
tau2 = learner2.effect(data[X])
return np.mean((tau - tau2)**2)
compare_methods(learners, names, loss_pred, 'Prediction to Prediction Loss')
| learner | loss | |
|---|---|---|
| 0 | SL | 0.000000 |
| 1 | TL | 0.007342 |
| 2 | XL | 0.000366 |
| 3 | RL | 0.134137 |
| 4 | DRL | 0.000933 |
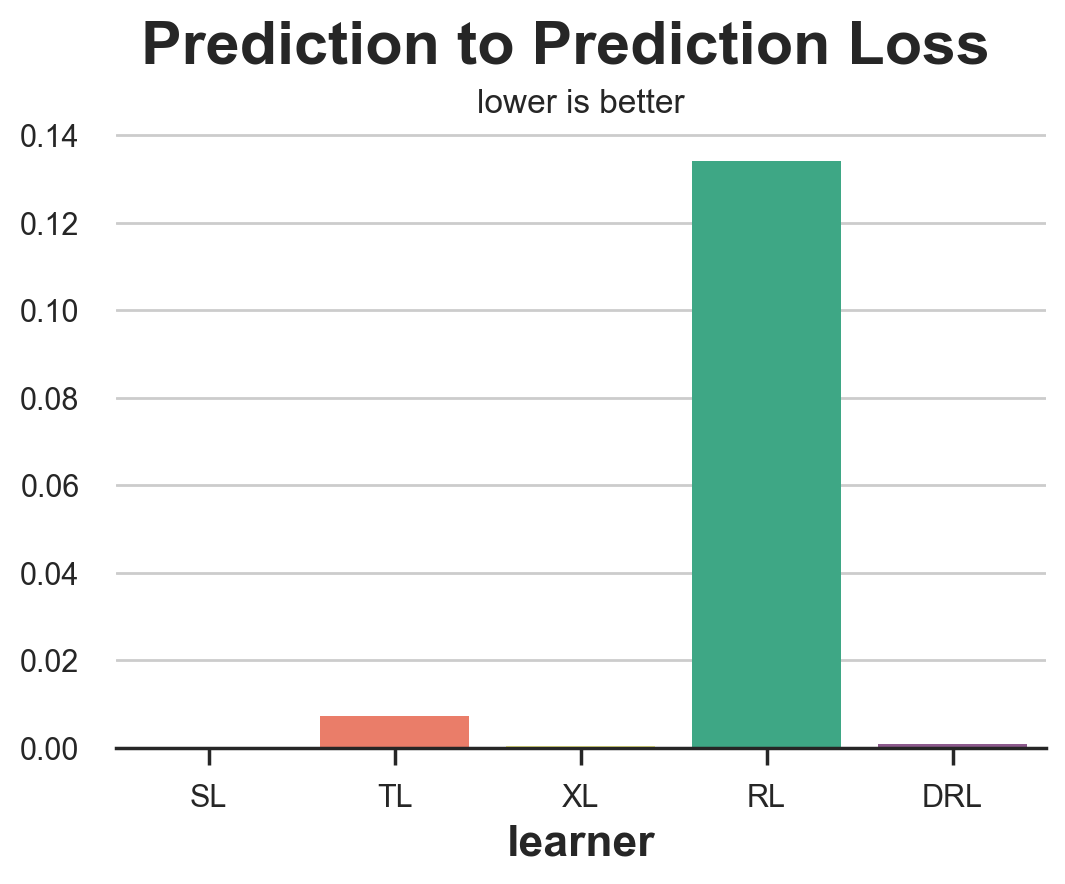
Unsurprisingly, this metric performs extremely bad, and you should never use it, since it rewards models that are consistent, irrespectively of their quality. A model that always predicts a random constant CATE for each observations would obtain a perfect score.
Distribution Loss
A different approach is to ask: how well can we match the distribution of potential outcomes? We can do this exarcise for either the treated or untreated potential outcomes. Let’s take the last case. Suppose we take the observed sales for customers that did not receive the mail and the observed sales minus the estimated CATE $\hat{\tau}(x)$ for customers that did receive the mail. By the unconfoundedness assumption, these two distributions of the untreated potential outcome should be similar, conditional on covariates $X$.
Therefore, we expect the distance between the two distributions to be close if we correctly estimated the treatment effects. $$ dist \ \Big( \ {Y_i, X_i | W_i=0 } \ , \ {Y_i - \hat{\tau}(X_i), X_i | W_i=1 } \ \Big) $$
We can also do the same exercise for the treated potential outcome.
$$ dist \ \Big( \ {Y_i + \hat{\tau}(X_i), X_i | W_i=0 } \ , \ {Y_i, X_i | W_i=1 } \ \Big) $$
from dcor import energy_distance
def loss_dist(data, learner):
tau = learner.effect(data[X])
data.loc[data.mail==1, 'sales'] -= tau[data.mail==1]
return energy_distance(data.loc[data.mail==0, [Y] + X], data.loc[data.mail==1, [Y] + X], exponent=2)
compare_methods(learners, names, loss_dist, 'Distribution Loss')
| learner | loss | |
|---|---|---|
| 0 | SL | 1.728523 |
| 1 | TL | 1.733941 |
| 2 | XL | 1.733993 |
| 3 | RL | 1.736704 |
| 4 | DRL | 1.735105 |
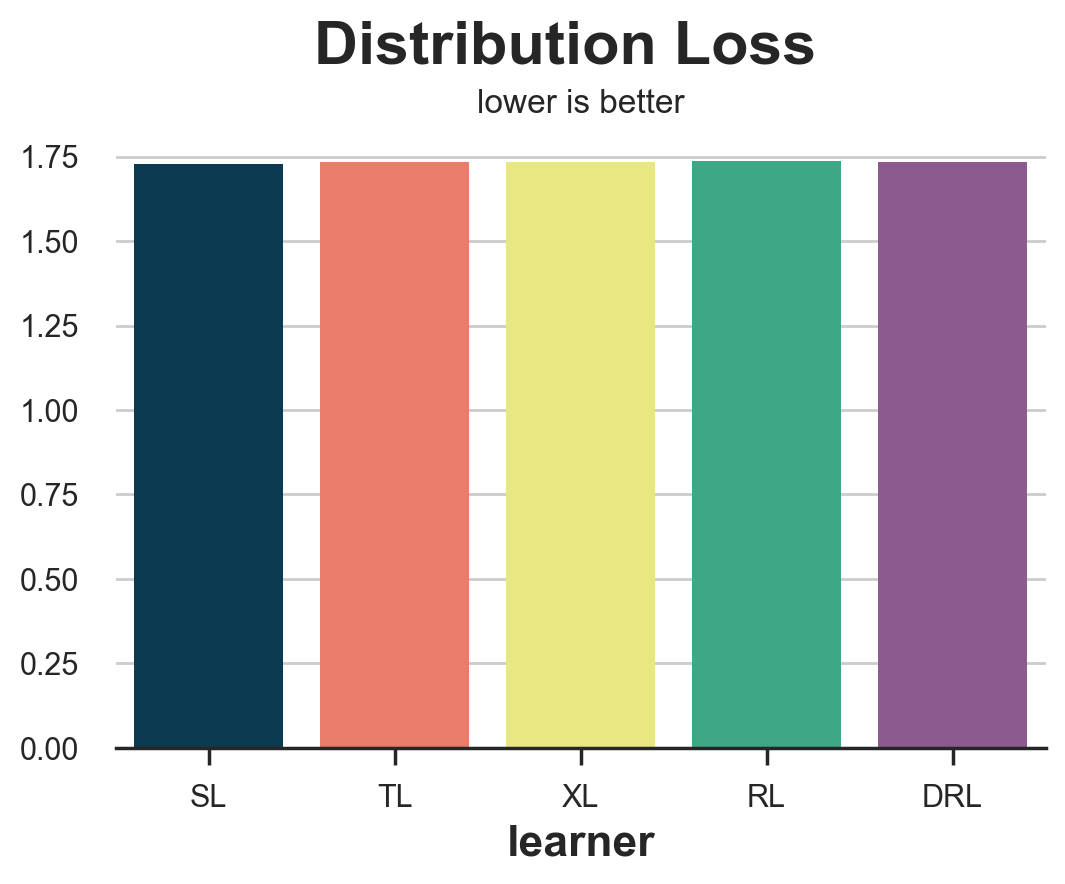
This measure is extremely noisy and rewards the S-learner followed by the T-learner which are actually the two worst performing models.
Above-below Median Difference
The above-below median loss tries to answer the question: is our uplift model detecting any heterogeneity? In particular, if we take the validation set and we split the sample into above-median and below median predicted uplift $\hat{\tau}(x)$, how big is the actual difference in average effect, estimated with a difference-in-means estimator? We would expect better estimators to better split the sample into high-effects and low-effects.
from statsmodels.formula.api import ols
def loss_ab(data, learner):
tau = learner.effect(data[X]) + np.random.normal(0, 1e-8, len(data))
data['above_median'] = tau >= np.median(tau)
param = ols('sales ~ mail * above_median', data=data).fit().params[-1]
return param
compare_methods(learners, names, loss_ab, title='Above-below Median Difference', subtitle='higher is better')
| learner | loss | |
|---|---|---|
| 0 | SL | -0.008835 |
| 1 | TL | 0.221423 |
| 2 | XL | 0.093177 |
| 3 | RL | 0.134629 |
| 4 | DRL | 0.075319 |
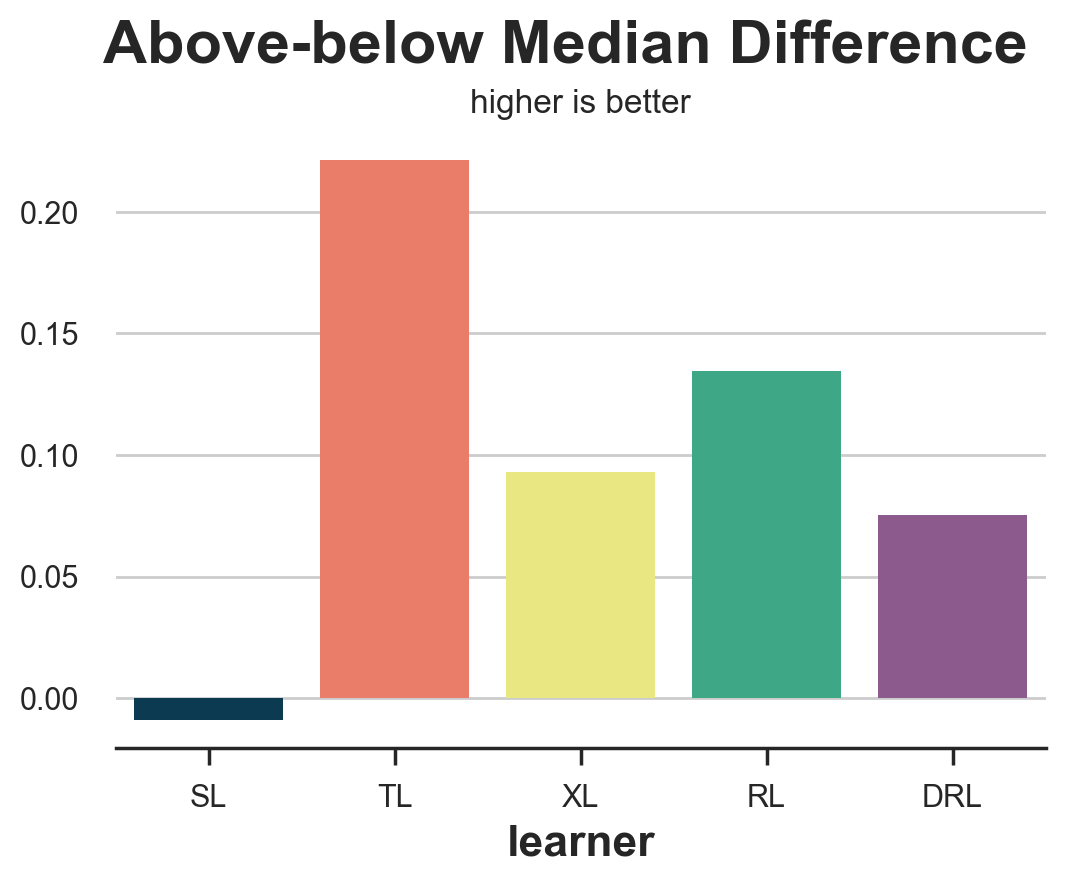
Unfortunately, the above-below median difference rewards the T-learner, which is among the worst performing models.
It’s important to note that the difference-in-means estimators in the two groups (above- and below- median $\hat{\tau}(x)$) are not guaranteed to be unbiased, even if the data came from a randomized experiment. In fact, we have split the two groups on a variable, $\hat{\tau}(x)$, that is highly endogenous. Therefore, the method should be used with a grain of salt.
Uplift Curve
An extension of the above-below median test is the uplift curve. The idea is simple: instead of splitting the sample into two groups based on the median (0.5 quantile), why not split the data into more groups (more quantiles)?
For each group, we compute the difference-in-means estimate, and we plot its cumulative sum against the corresponding quantile. The result is called uplift curve. The interpretation is simple: the higher the curve, the better we are able to separate high- from low-effect observations. However, also the same disclaimer applies: the difference-in-means estimates are not unbiased. Therefore, they should be used with a grain of salt.
def generate_uplift_curve(df):
Q = 20
df_q = pd.DataFrame()
data = dgp.generate_data(seed_data=1, seed_assignment=1, keep_po=True)
ate = np.mean(data[Y][data[W]==1]) - np.mean(data[Y][data[W]==0])
for learner, name in zip(learners, names):
data['tau_hat'] = learner.effect(data[X])
data['q'] = pd.qcut(-data.tau_hat + np.random.normal(0, 1e-8, len(data)), q=Q, labels=False)
for q in range(Q):
temp = data[data.q <= q]
uplift = (np.mean(temp[Y][temp[W]==1]) - np.mean(temp[Y][temp[W]==0])) * q / (Q-1)
df_q = pd.concat([df_q, pd.DataFrame({'q': [q], 'uplift': [uplift], 'learner': [name]})], ignore_index=True)
fig, ax = plt.subplots(1, 1, figsize=(8, 5))
sns.lineplot(x=range(Q), y=ate*range(Q)/(Q-1), color='k', ls='--', lw=3)
sns.lineplot(x='q', y='uplift', hue='learner', data=df_q);
plt.suptitle('Uplift Curve', y=1.02, fontsize=28, fontweight='bold')
plt.title('higher is better', fontsize=14, fontweight=None, y=0.96)
generate_uplift_curve(df)
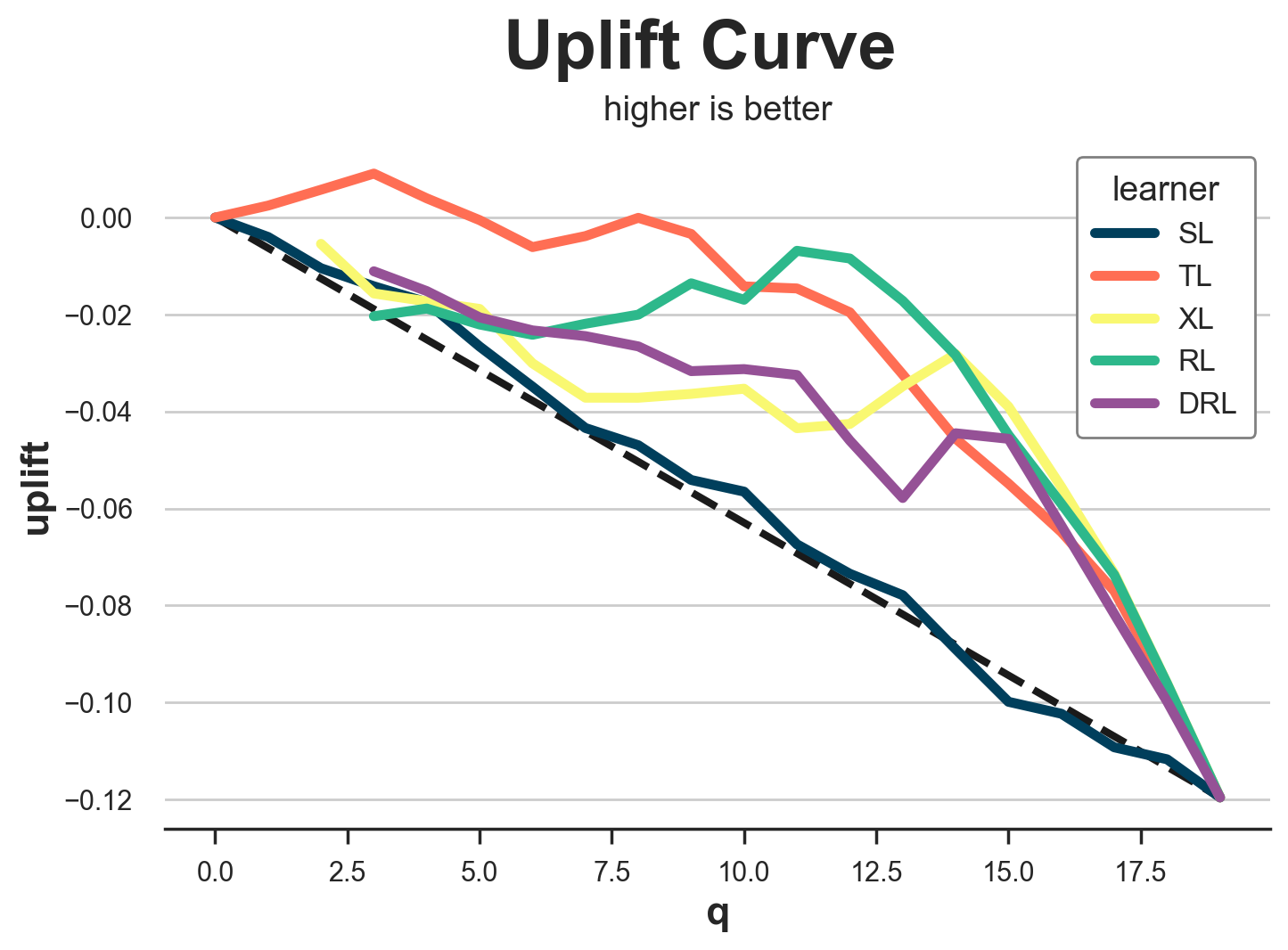
While probably not the best method to evaluate uplift models, the uplift curve is very important in understanding and implementing them. In fact, for each model, it tells us that is the expected average treatment effect (y-axis) as we increase the share of the treated population (x-axis).
Nearest Neighbor Match
The last couple of methods we analyzed, aggregated data in order to understand whether the methods work on larger groups. The nearest neighbor match tries instead to understand how well an uplift model predicts individual treatment effects. However, since the ITEs are not observable, it tries to build a proxy by matching treated and control observations on observable characteristics $X$.
For example, if we take all treated observations ($i: W_i=1$), and we find the nearest neighbor in the control group ($NN_0(X_i)$), the corresponding MSE loss function is $$ \mathcal{L} _ {NN}(\hat{\tau}) = \frac{1}{n} \sum _ {i: W_i=1} \Big( \hat{\tau}(X_i) - (Y_i - NN_0(X_i)) \Big)^2 $$
from scipy.spatial import KDTree
def loss_nn(data, learner):
tau_hat = learner.effect(data[X])
nn0 = KDTree(data.loc[data[W]==0, X].values)
control_index = nn0.query(data.loc[data[W]==1, X], k=1)[-1]
tau_nn = data.loc[data[W]==1, Y].values - data.iloc[control_index, :][Y].values
return np.mean((tau_hat[data[W]==1] - tau_nn)**2)
compare_methods(learners, names, loss_nn, title='Nearest Neighbor Loss')
| learner | loss | |
|---|---|---|
| 0 | SL | 0.050478 |
| 1 | TL | 0.051301 |
| 2 | XL | 0.047102 |
| 3 | RL | 0.046684 |
| 4 | DRL | 0.046652 |
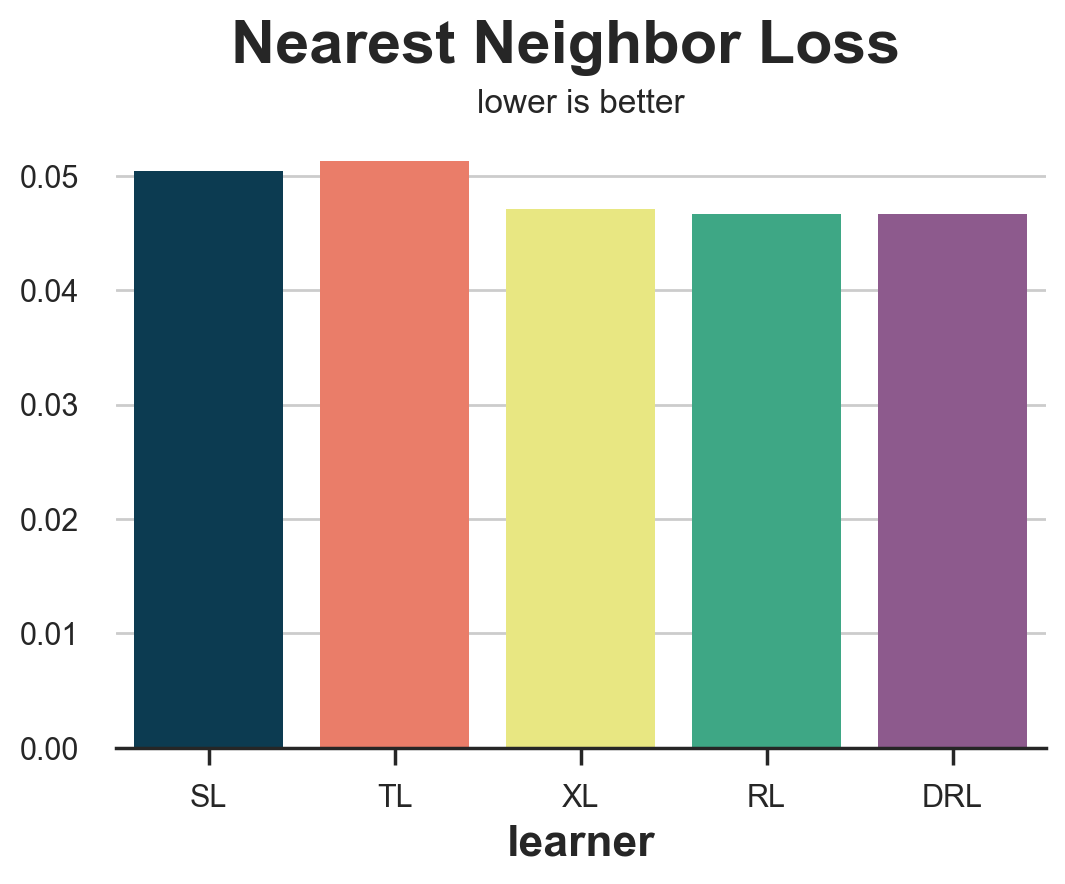
In this case, the nearest neighbor loss performs quite well, identifying the two worse performing methods, the S- and T-learner.
IPW Loss
The Inverse Probability Weighting (IPW) loss function was first proposed by Gutierrez, Gerardy (2017), and it is the first of three metrics that we are going to see that uses a pseudo-outcome $Y^{*}$ to evaluate the estimator. Pseudo-outcomes are variables whose expected value is the Conditional Average Treatment Effect, but that are too volatile to be directly used as estimates. For a more detailed explanation of pseudo-outcomes, I suggest my article on causal regression trees. The pseudo-outcome corresponding to the IPW loss is $$ Y^* _ {IPW} = Y_i \frac{W_i - \hat{e}(X_i)}{\hat{e}(X_i)(1 - \hat{e}(X_i))} $$
so that the corresponding loss function is $$ \mathcal{L} _ {IPW} = \frac{1}{n} \sum_{i=1}^{n} \left( \hat{\tau}(X_i) - Y_i \ \frac{W_i - \hat{e}(X_i)}{\hat{e}(X_i)(1 - \hat{e}(X_i))} \right)^2 $$
def loss_ipw(data, learner):
tau_hat = learner.effect(data[X])
e_hat = clone(model_e).fit(data[X], data[W]).predict_proba(data[X])[:,1]
tau_gg = data[Y] * (data[W] - e_hat) / (e_hat * (1 - e_hat))
return np.mean((tau_hat - tau_gg)**2)
compare_methods(learners, names, loss_ipw, title='IPW Loss')
| learner | loss | |
|---|---|---|
| 0 | SL | 1.170917 |
| 1 | TL | 1.153752 |
| 2 | XL | 1.172517 |
| 3 | RL | 1.172934 |
| 4 | DRL | 1.171769 |
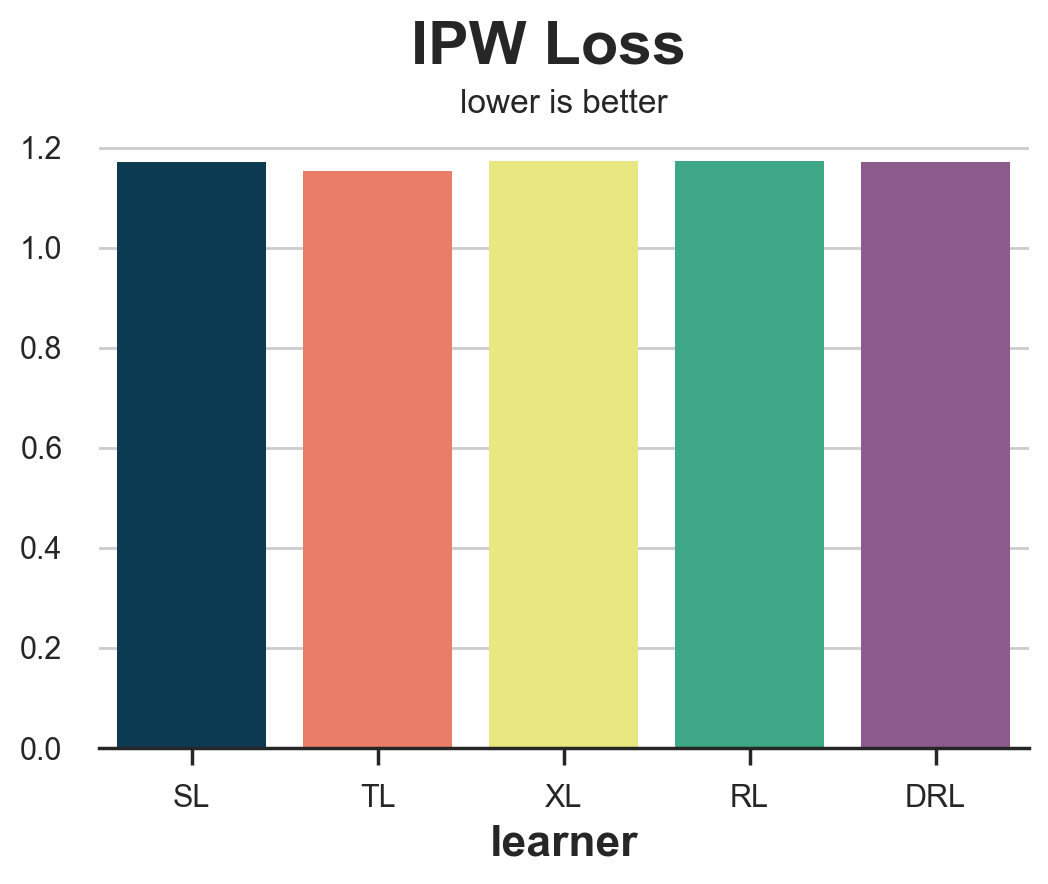
The IPW loss is extremely noisy. A solution is to use its more robust variations, the R-loss or the DR-loss which we present next.
R Loss
The R-loss was introduced together with the R-learner by Nie, Wager (2017), and it is essentially the objective function of the R-learner. As for the IPW-loss, the idea is to try to match a pseudo outcome whose expected value is the Conditional Average Treatment Effect. $$ Y^* _ {R} = \frac{Y_i - \hat{\mu}_W(X_i)}{W_i - \hat{e}(X_i)} $$
The corresponding loss function is $$ \mathcal{L}_{R} = \frac{1}{n} \sum _ {i=1}^{n} \left( \hat{\tau}(X_i) - \frac{Y_i - \hat{\mu}_W(X_i)}{W_i - \hat{e}(X_i)} \right)^2 $$
def loss_r(data, learner):
tau_hat = learner.effect(data[X])
y_hat = clone(model_y).fit(df[X + [W]], df[Y]).predict(data[X + [W]])
e_hat = clone(model_e).fit(df[X], df[W]).predict_proba(data[X])[:,1]
tau_nw = (data[Y] - y_hat) / (data[W] - e_hat)
return np.mean((tau_hat - tau_nw)**2)
results = compare_methods(learners, names, loss_r, title='R Loss')
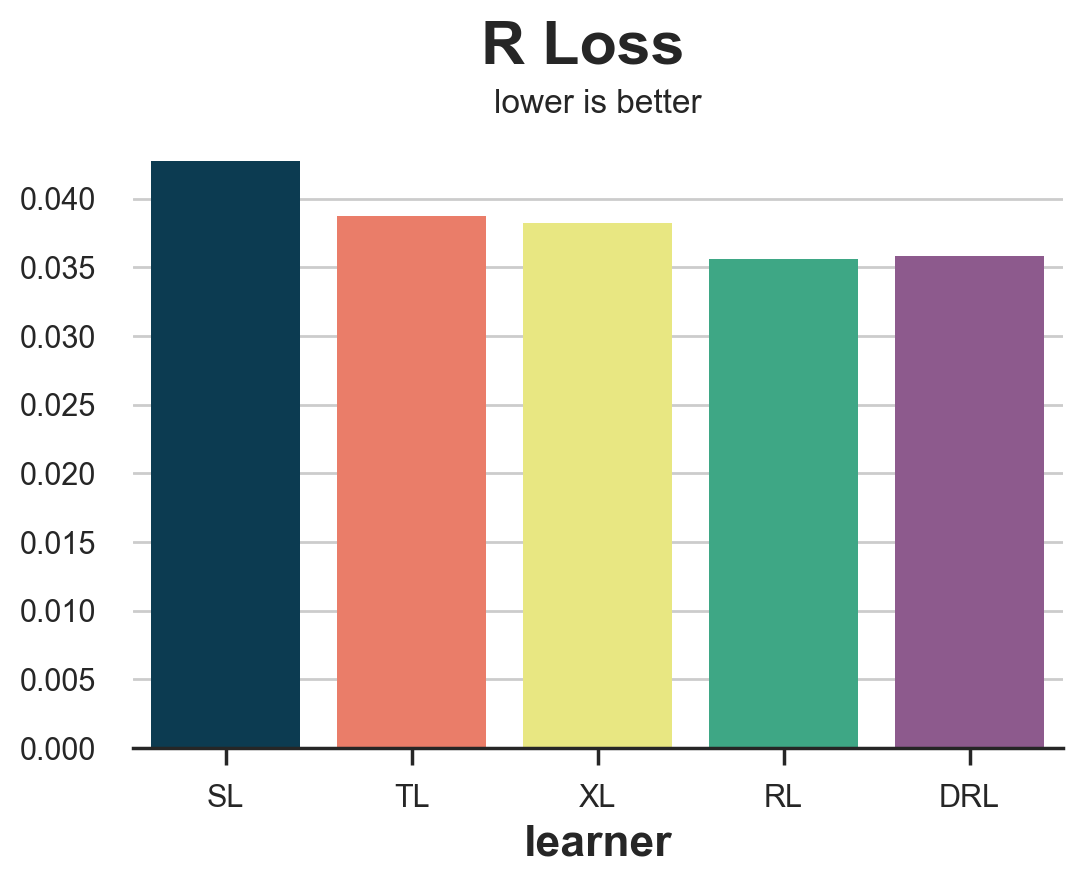
The R-loss is sensibly less noisy than the IPW loss and it clearly isolates the S-learner. However, it tends to favor its corresponding learner, the R-learner.
DR Loss
The DR-loss is the objective function of the DR-learner, and it was first introduced by Saito, Yasui (2020). As for the IPW- and the R-loss, the idea is to try to match a pseudo outcome, whose expected value is the Conditional Average Treatment Effect. The DR pseudo-outcome is strongly related to the AIPW estimator, also known as doubly-robust estimator, hence the DR name. $$ Y^* _ {DR} = \hat{\mu}_1(X_i) - \hat{\mu}_0(X_i) + (Y_i - \hat{\mu}_W(X_i)) \ \frac{W_i - \hat{e}(X_i)}{\hat{e}(X_i)(1 - \hat{e}(X_i))} $$
The corresponding loss function is $$ \mathcal{L} _ {DR} = \frac{1}{n} \sum _ {i=1}^{n} \left( \hat{\tau}(X_i) - \hat{\mu}_1(X_i) + \hat{\mu}_0(X_i) - (Y_i - \hat{\mu}_W(X_i)) \ \frac{W_i - \hat{e}(X_i)}{\hat{e}(X_i)(1 - \hat{e}(X_i))} \right)^2 $$
def loss_dr(data, learner):
tau_hat = learner.effect(data[X])
y_hat = clone(model_y).fit(df[X + [W]], df[Y]).predict(data[X + [W]])
mu1 = clone(model_y).fit(df[X + [W]], df[Y]).predict(data[X + [W]].assign(mail=1))
mu0 = clone(model_y).fit(df[X + [W]], df[Y]).predict(data[X + [W]].assign(mail=0))
e_hat = clone(model_e).fit(df[X], df[W]).predict_proba(data[X])[:,1]
tau_nw = mu1 - mu0 + (data[Y] - y_hat) * (data[W] - e_hat) / (e_hat * (1 - e_hat))
return np.mean((tau_hat - tau_nw)**2)
results = compare_methods(learners, names, loss_dr, title='DR Loss')
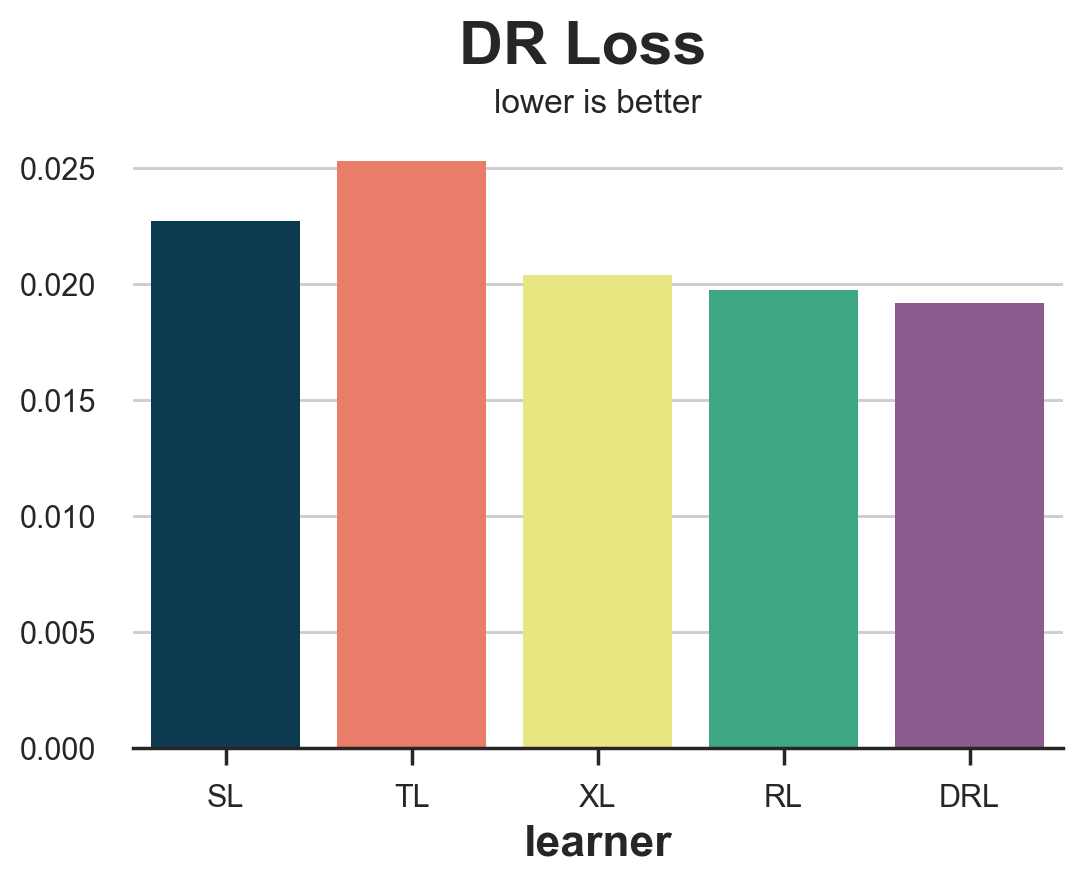
As for the R-loss, the DR-loss tends to favor its corresponding learner, the DR-learner. However, it provides a more accurate ranking in terms of algorithms’ accuracy.
Empirical Policy Gain
The last loss function that we are going to analyze is different from all the others we have seen so far since it does not focus on how well we are able to estimate the treatment effects but rather on how well would the corresponding optimal treatment policy performs. In particular, Hitsch, Misra, Zhang (2023) propose the following gain function:
$$ \mathcal{G} _ {HMZ} = \sum _ {i=1}^{n} \left( W_i \cdot d(\hat{\tau}) \cdot \frac{Y_i - c}{\hat{e}(X_i)} + (1-W_i) \cdot (1-d(\hat{\tau})) \cdot \frac{Y_i}{1-\hat{e}(X_i)} \right) $$
where $c$ is the treatment cost and $d$ is the optimal treatment policy given the estimated CATE $\hat{\tau}(X_i)$. In our case, we assume an individual treatment cost of $c=0.01$\$, so that the optimal policy is to treat every customer with an estimated CATE larger than 0.01.
The terms $W_i \cdot d(X_i)$ and $(1-W_i) \cdot (1-d(X_i))$ imply that we use for the calculation only individuals for whom the actual treatment W corresponds with the optimal one, d.
def gain_policy(data, learner):
tau_hat = learner.effect(data[X])
e_hat = clone(model_e).fit(data[X], data[W]).predict_proba(data[X])[:,1]
d = tau_hat > cost
return np.sum((d * data[W] * (data[Y] - cost)/ e_hat + (1-d) * (1-data[W]) * data[Y] / (1-e_hat)))
results = compare_methods(learners, names, gain_policy, title='Empirical Policy Gain', subtitle='higher is better')
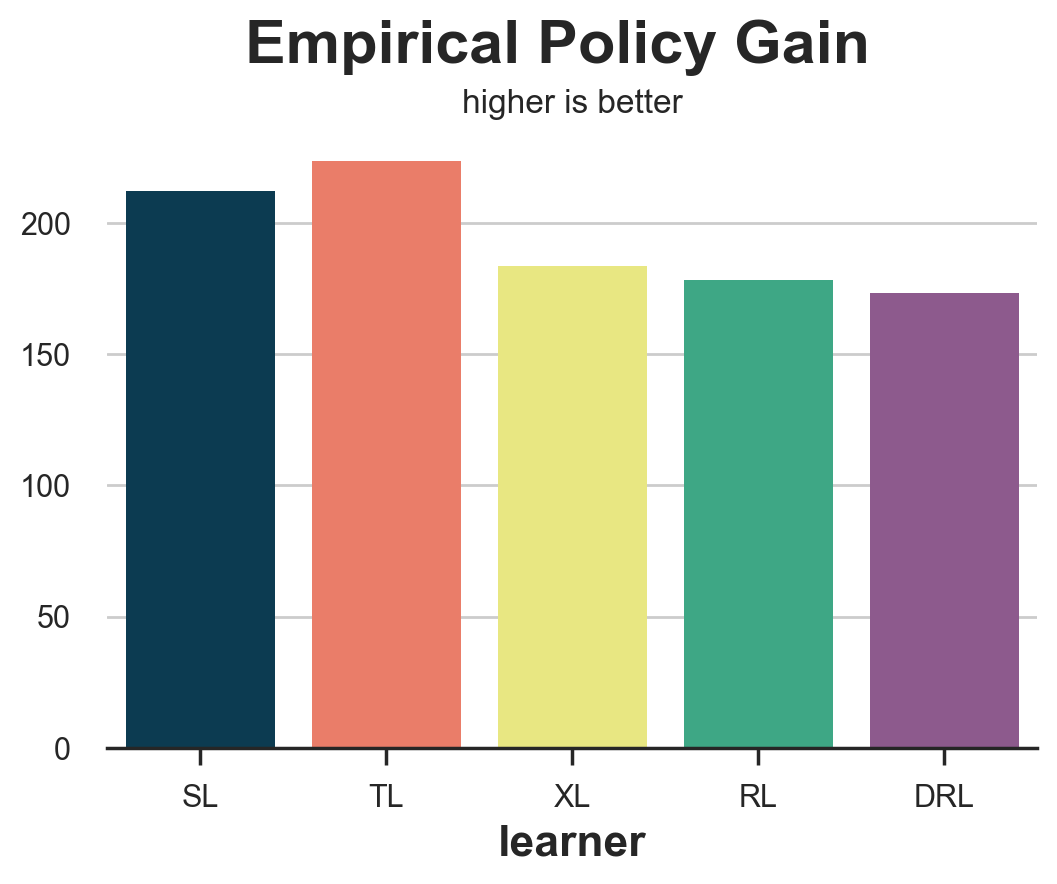
The empirical policy gain performs very well, isolating the two worst performing methods, the S- and T-learners.
Meta Studies
In this article we have introduced a wide variety of methods to evaluate uplift models, a.k.a. Conditional Average Treatment Effect estimators. We have also tested in our simulated dataset, which is a very special and limited example. How do these metrics perform in general?
Schuler, Baiocchi, Tibshirani, Shah (2018) compares the S-loss, T-loss, R-loss, on simulated data, for the corresponding estimators. They find that the R-loss “is the validation set metric that, when optimized, most consistently leads to the selection of a high-performing model”. The authors also detect the so-called congeniality bias: metrics such as the R- or DR-loss tend to be biased towards the corresponding learner.
Curth, van der Schaar (2023) studies a broader array of learners from a theoretical perspective. They find that “no existing selection criterion is globally best across all experimental conditions we consider”.
Mahajan, Mitliagkas, Neal, Syrgkanis (2023) is the most comprehensive study in terms of scope. The authors compare many metrics on 144 datasets and 415 estimators. They find that “no metric significantly dominates the rest” but “metrics that use DR elements seem to always be among the candidate winners”.
Conclusion
In this article, we have explored multiple methods to evaluate uplift models. The main challenge is the unobservability of the variable of interest, the Individual Treatment Effects. Therefore, different methods try to evaluate uplift models either using other variables, using proxy outcomes, or approximating the effect of implied optimal policies.
It is hard to recommend using a single method since there is no consensus on which one performs best, neither from a theoretical nor from an empirical perspective. Loss functions that use R- and DR- elements tend to perform consistently better, but are also biased towards the corresponding learners. Understanding how these metrics work, however, can help in understanding their biases and limitations in order to make the most appropriate decisions depending on the specific scenario.
References
-
Curth, van der Schaar (2023), “In Search of Insights, Not Magic Bullets: Towards Demystification of the Model Selection Dilemma in Heterogeneous Treatment Effect Estimation”
-
Gutierrez, Gerardy (2017), “Causal Inference and Uplift Modeling: A review of the literature”
-
Hitsch, Misra, Zhang (2023), “Heterogeneous Treatment Effects and Optimal Targeting Policy Evaluation”
-
Kennedy (2022), “Towards optimal doubly robust estimation of heterogeneous causal effects”
-
Kunzel, Sekhon, Bickel, Yu (2017), “Meta-learners for Estimating Heterogeneous Treatment Effects using Machine Learning”
-
Mahajan, Mitliagkas, Neal, Syrgkanis (2023), “Empirical Analysis of Model Selection for Heterogeneous Causal Effect Estimation”
-
Nie, Wager (2017), “Quasi-Oracle Estimation of Heterogeneous Treatment Effects”
-
Saito, Yasui (2020), “Counterfactual Cross-Validation: Stable Model Selection Procedure for Causal Inference Models”
-
Schuler, Baiocchi, Tibshirani, Shah (2018), “A comparison of methods for model selection when estimating individual treatment effects”
Related Articles
Code
You can find the original Jupyter Notebook here:
https://github.com/matteocourthoud/Blog-Posts/blob/main/notebooks/evaluate_uplift.ipynb
I hold a PhD in economics from the University of Zurich. Now I work at the intersection of economics, data science and statistics. I regularly write about causal inference on Medium.